python으로 만든 네이버 폐지 줍는 코드입니다.
requirements.txt는 다음과 같습니다.
bs4==0.0.1
beautifulsoup4==4.12.2
certifi==2023.11.17
charset-normalizer==3.3.2
idna==3.6
selenium==4.16.0
requests==2.31.0
soupsieve==2.5
urllib3==2.1.0
webdriver-manager==4.0.1
chromedrivermanager==0.0.1
사용하는 크롬은 120으로 아래의 사이트에서 드라이버를 받으시면 됩니다.
python 코드는 다음과 같습니다. 이름은 naver_paper.py 입니다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
import time
import requests
from urllib.parse import urljoin
from bs4 import BeautifulSoup
def find_naver_campaign_links(base_url, visited_urls_file='visited_urls.txt'):
# Read visited URLs from file
try:
with open(visited_urls_file, 'r') as file:
visited_urls = set(file.read().splitlines())
except FileNotFoundError:
visited_urls = set()
# Send a request to the base URL
response = requests.get(base_url)
soup = BeautifulSoup(response.text, 'html.parser')
# Find all span elements with class 'list_subject' and get 'a' tags
list_subject_links = soup.find_all('span', class_='list_subject')
naver_links = []
for span in list_subject_links:
a_tag = span.find('a', href=True)
if a_tag and '네이버' in a_tag.text:
naver_links.append(a_tag['href'])
# Initialize a list to store campaign links
campaign_links = []
# Check each Naver link
for link in naver_links:
full_link = urljoin(base_url, link)
print("naver_links - " + full_link)
if full_link in visited_urls:
continue # Skip already visited links
res = requests.get(full_link)
inner_soup = BeautifulSoup(res.text, 'html.parser')
# Find all links that start with the campaign URL
for a_tag in inner_soup.find_all('a', href=True):
if a_tag['href'].startswith("https://campaign2-api.naver.com"):
campaign_links.append(a_tag['href'])
# Add the visited link to the set
visited_urls.add(full_link)
# Save the updated visited URLs to the file
with open(visited_urls_file, 'w') as file:
for url in visited_urls:
file.write(url + '\n')
return campaign_links
# 크롬 드라이버 옵션 설정
chrome_options = webdriver.ChromeOptions()
# 새로운 창 생성
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
driver.get('https://naver.com')
# 현재 열려 있는 창 가져오기
current_window_handle = driver.current_window_handle
# <a href class='MyView-module__link_login___HpHMW'> 일때 해당 링크 클릭
driver.find_element(By.XPATH, "//a[@class='MyView-module__link_login___HpHMW']").click()
# 새롭게 생성된 탭의 핸들을 찾습니다
# 만일 새로운 탭이 없을경우 기존 탭을 사용합니다.
new_window_handle = None
for handle in driver.window_handles:
if handle != current_window_handle:
new_window_handle = handle
break
else:
new_window_handle = handle
# 새로운 탭을 driver2로 지정합니다
driver.switch_to.window(new_window_handle)
driver2 = driver
username = driver2.find_element(By.NAME, 'id')
pw = driver2.find_element(By.NAME, 'pw')
input_id="naver_id"
input_pw="naver_password"
# ID input 클릭
username.click()
# js를 사용해서 붙여넣기 발동 <- 왜 일부러 이러냐면 pypyautogui랑 pyperclip를 사용해서 복붙 기능을 했는데 운영체제때문에 안되서 이렇게 한거다.
driver2.execute_script("arguments[0].value = arguments[1]", username, input_id)
time.sleep(1)
pw.click()
driver2.execute_script("arguments[0].value = arguments[1]", pw, input_pw)
time.sleep(1)
#입력을 완료하면 로그인 버튼 클릭
driver2.find_element(By.CLASS_NAME, "btn_login").click()
time.sleep(1)
# The base URL to start with
base_url = "https://www.clien.net/service/board/jirum"
#base_url = "https://www.clien.net/service/board/park"
campaign_links = find_naver_campaign_links(base_url)
if(campaign_links == []):
print("모든 링크를 방문했습니다.")
for link in campaign_links:
print(link) # for debugging
# Send a request to the base URL
driver2.get(link)
try:
result = driver2.switch_to.alert
print(result.text)
result.accept()
except:
print("no alert")
pageSource = driver2.page_source
print(pageSource)
time.sleep(1)
time.sleep(10)
위의 코드에서 89라인과 90라인에 아이디와 암호를 넣으시면 됩니다.
폴더를 만드시고 같은 폴더안에 아래의 화일을 복사하시면 됩니다.
requirements.txt
naver_paper.py
chromedriver.exe
복사후에
pip install -r requirements.txt
으로 패키지를 설치하시고
실행은
python naver_paper.py
로 하시면 됩니다.
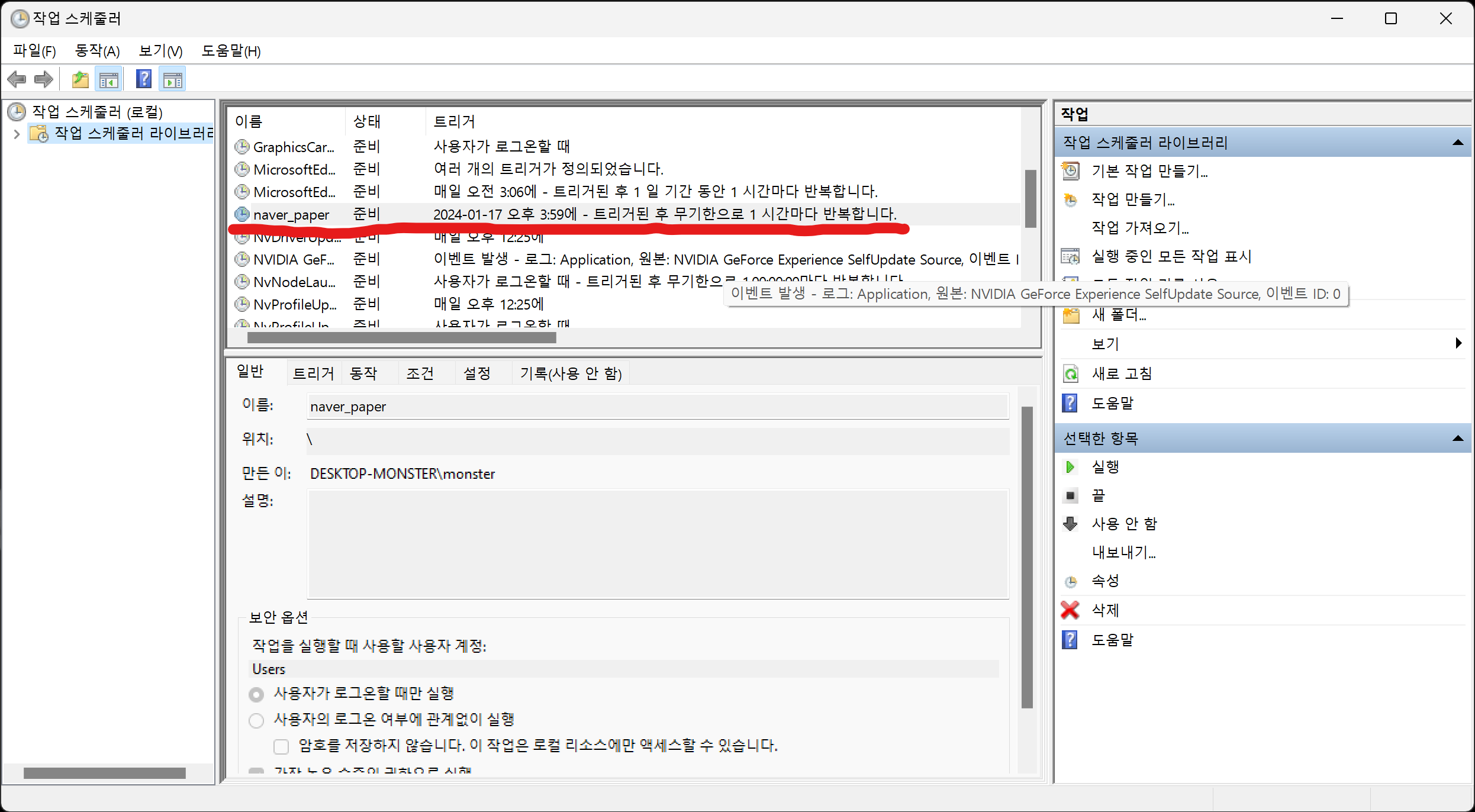
작업 스케줄러에 등록하시려면 다음과 같습니다.
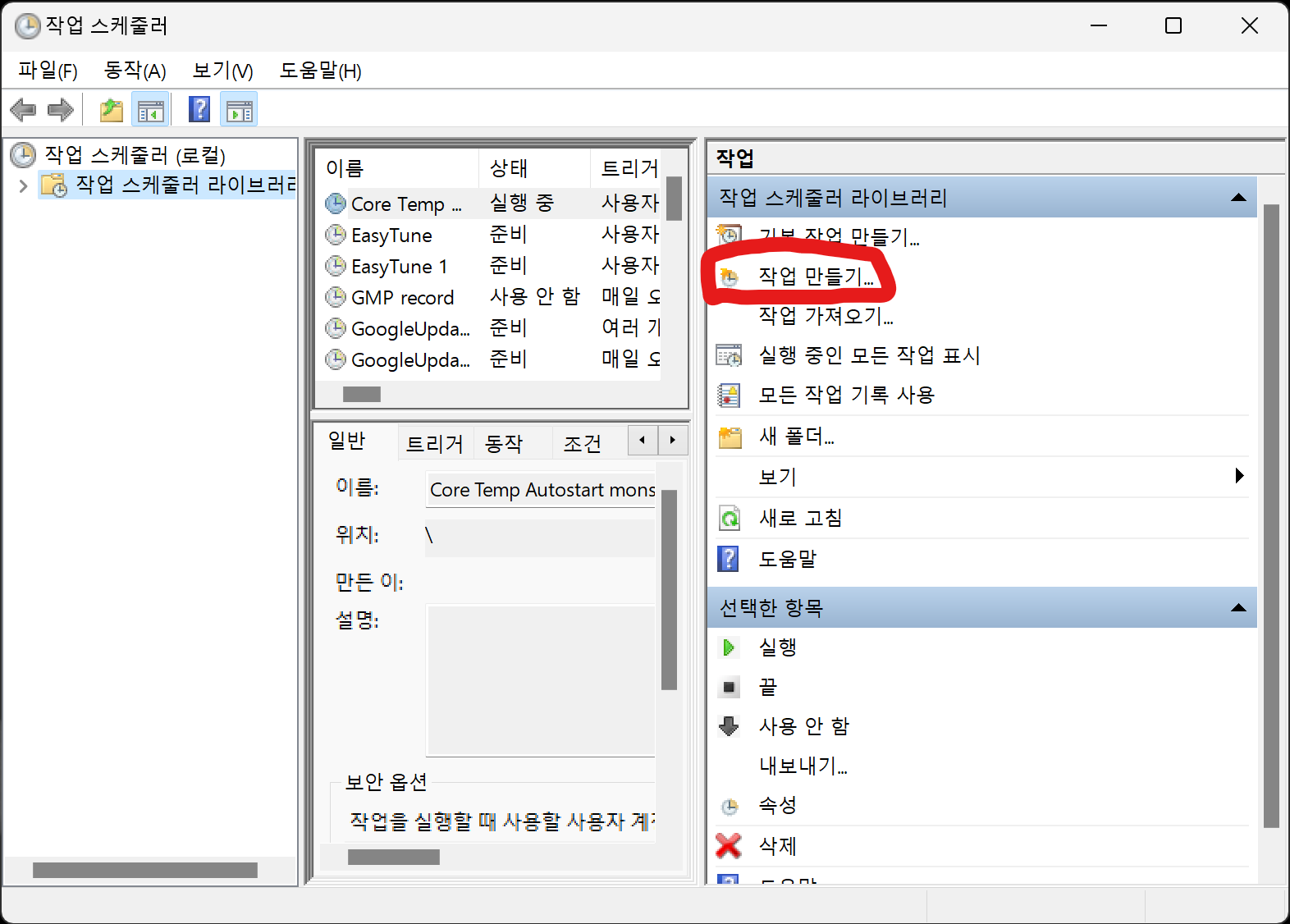
이름은 naver_paper로 합니다.
사용자는 Users로 변경합니다. (추후 수정시 오류가 발생하지 않게 합니다.)
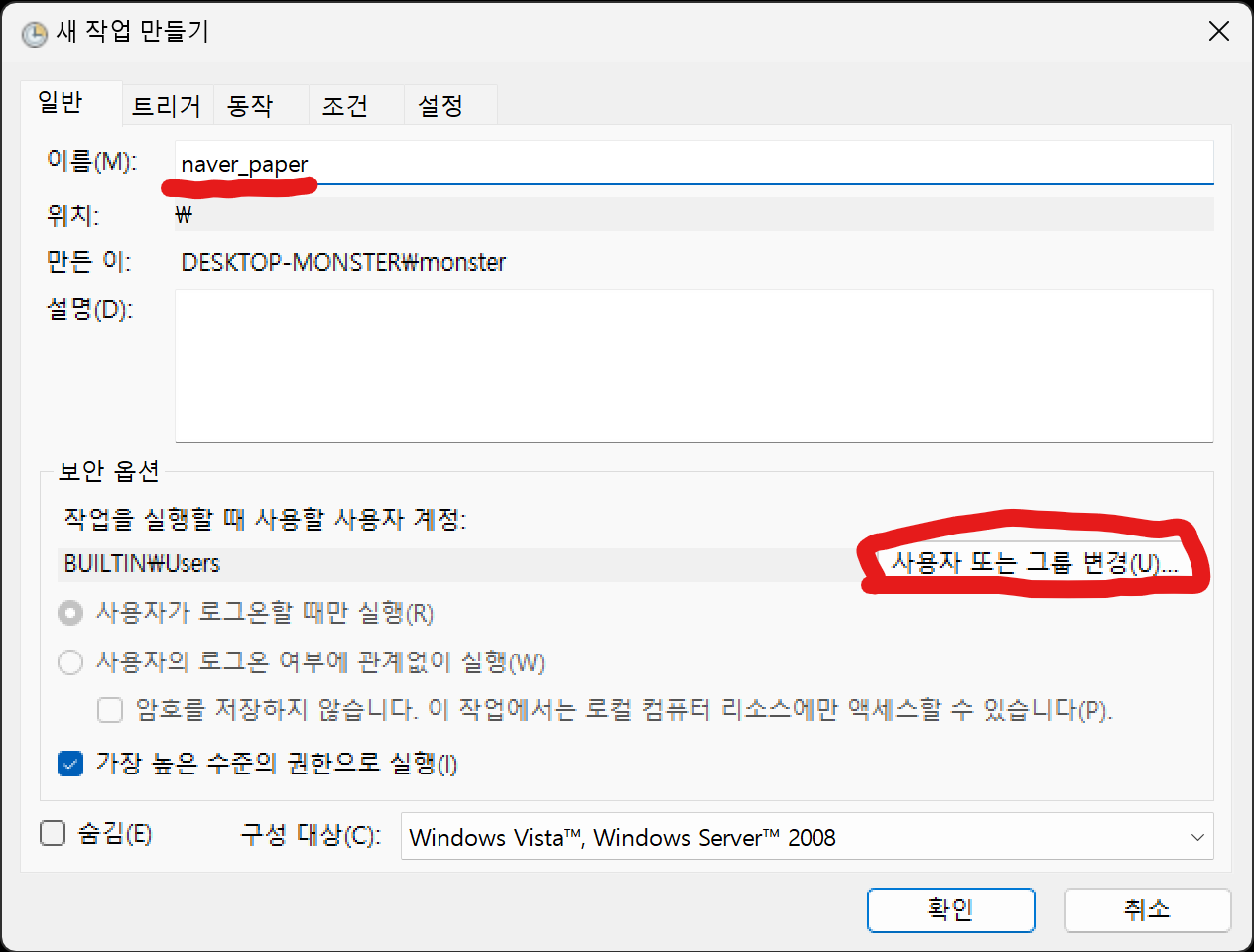
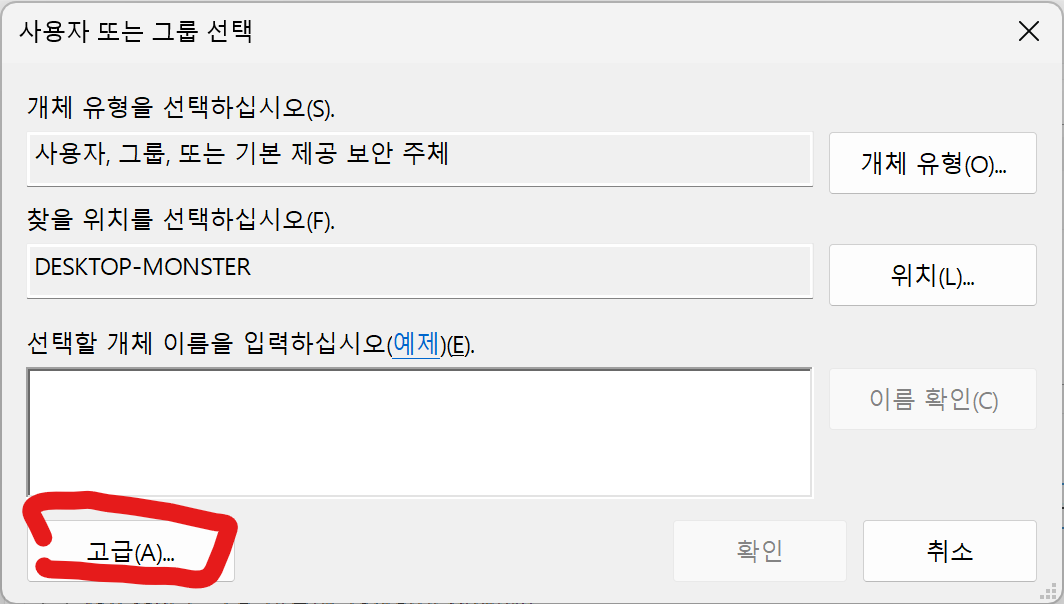
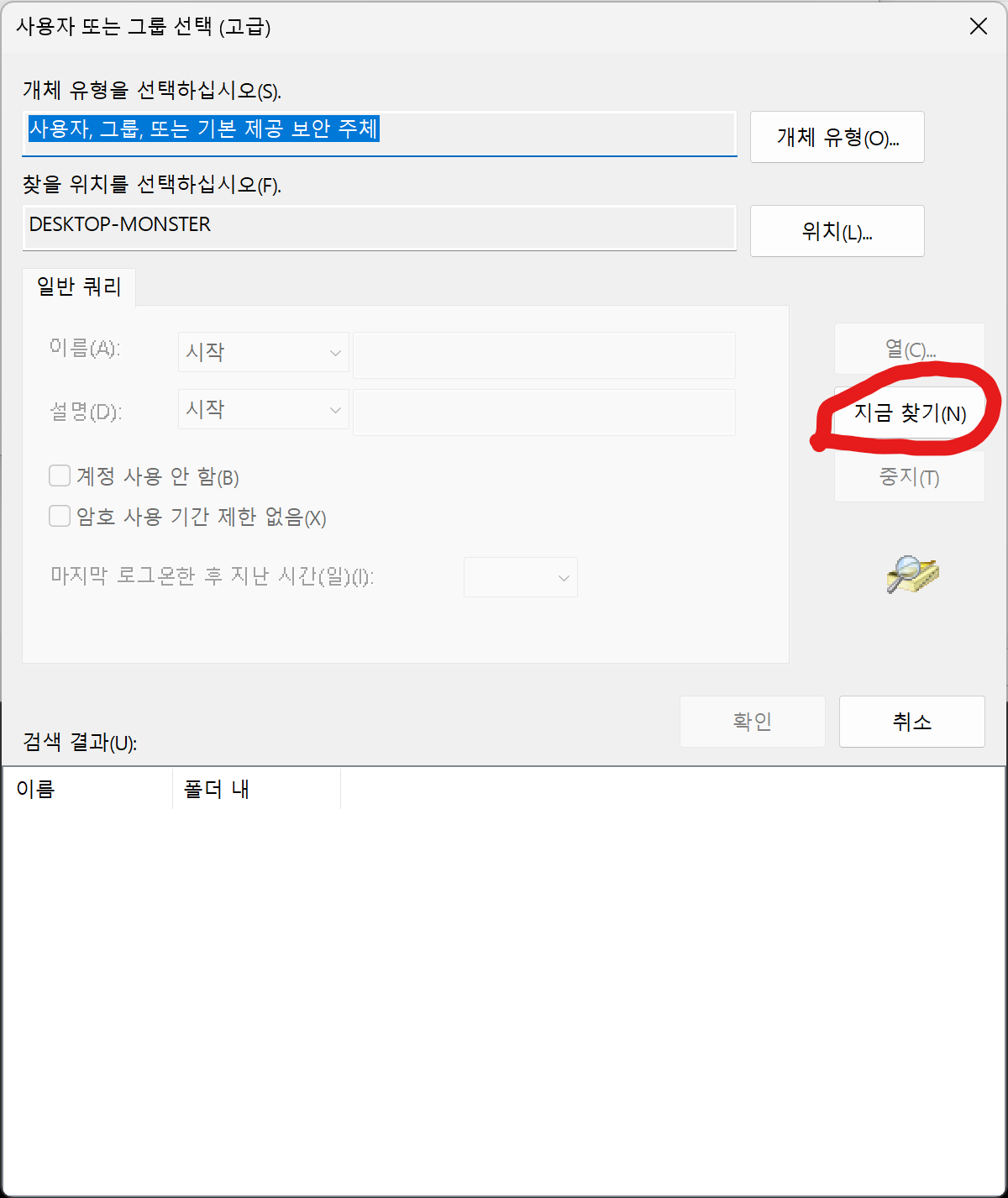
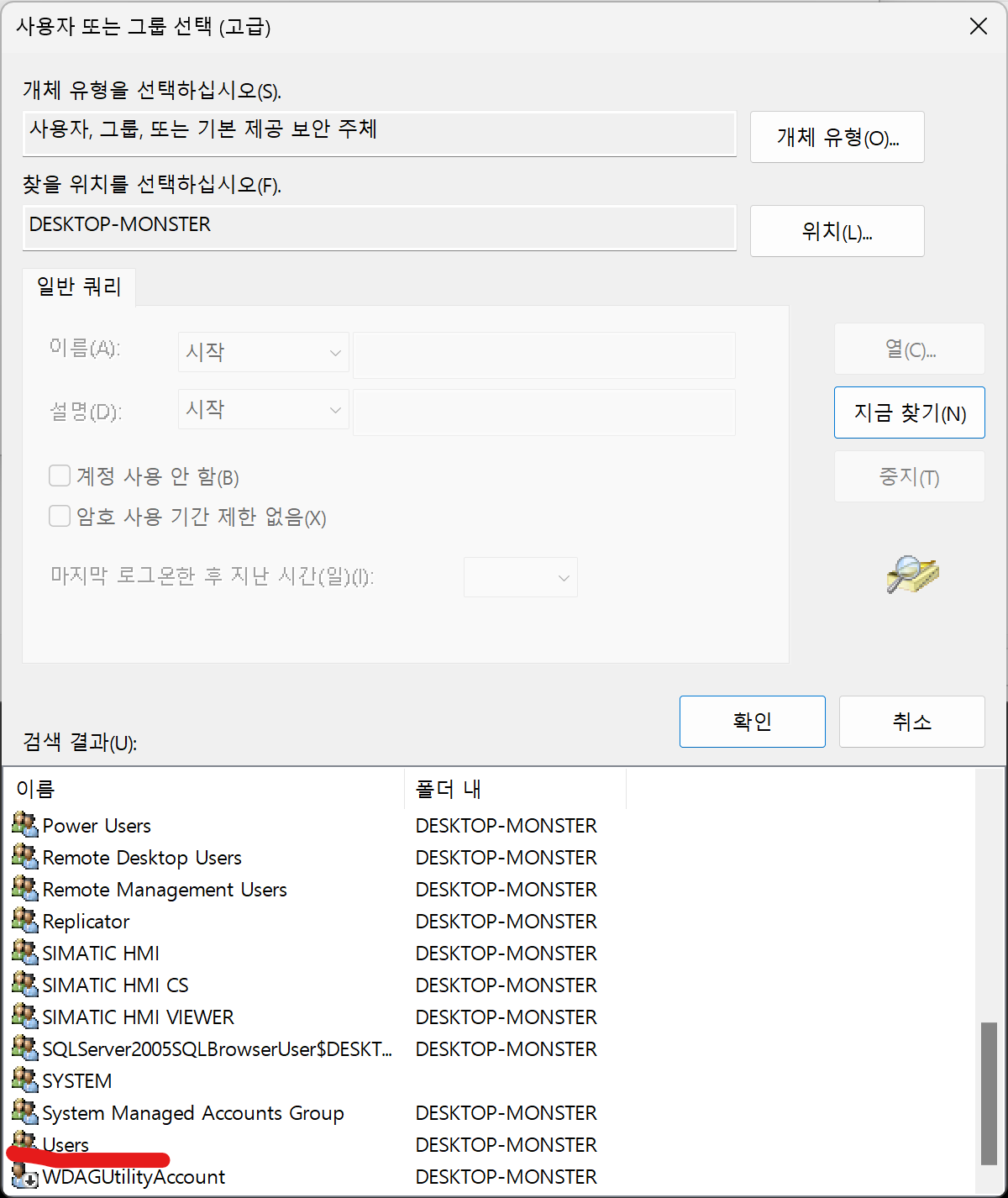
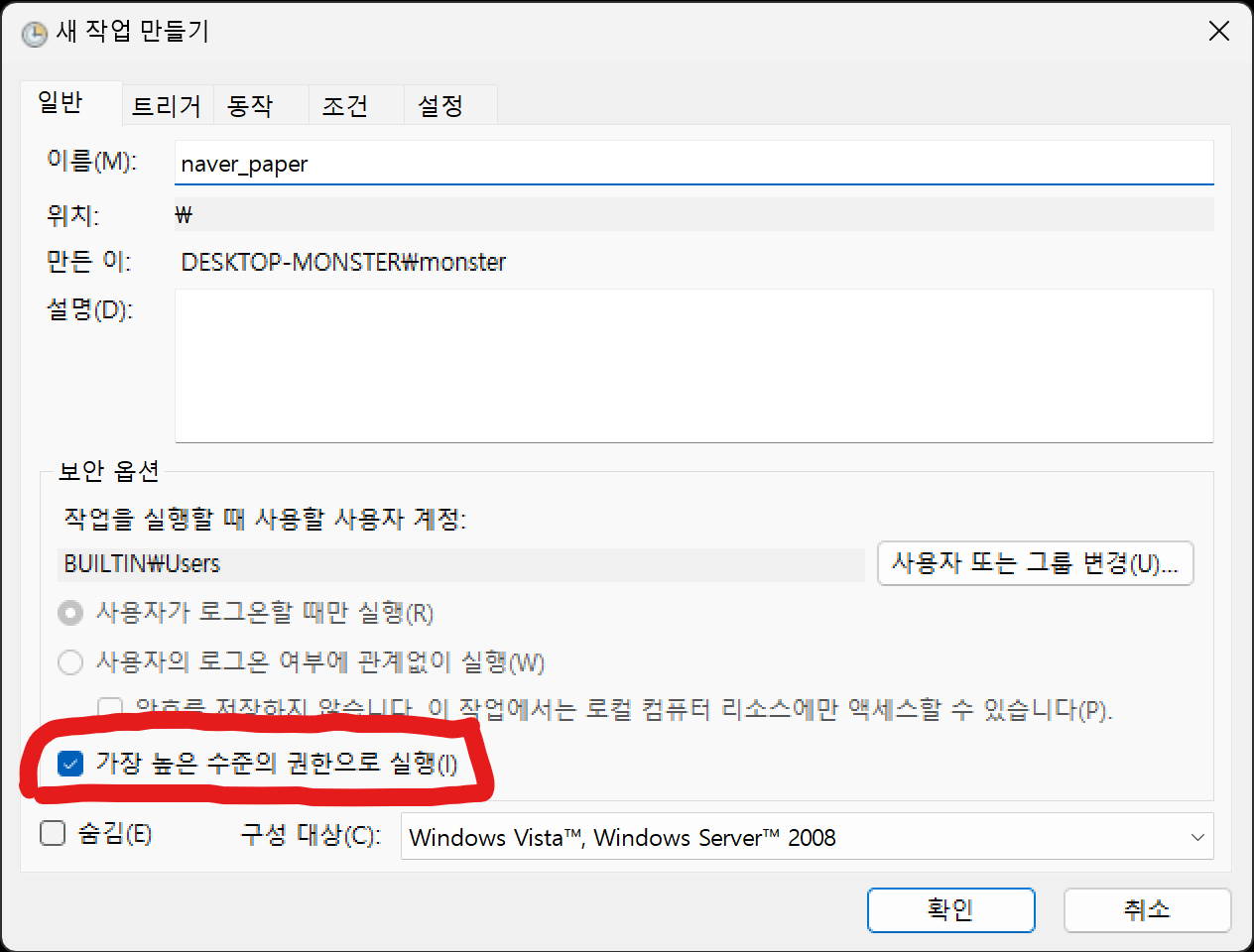
실행은 가장 높은 수준의 권한으로 변경합니다.
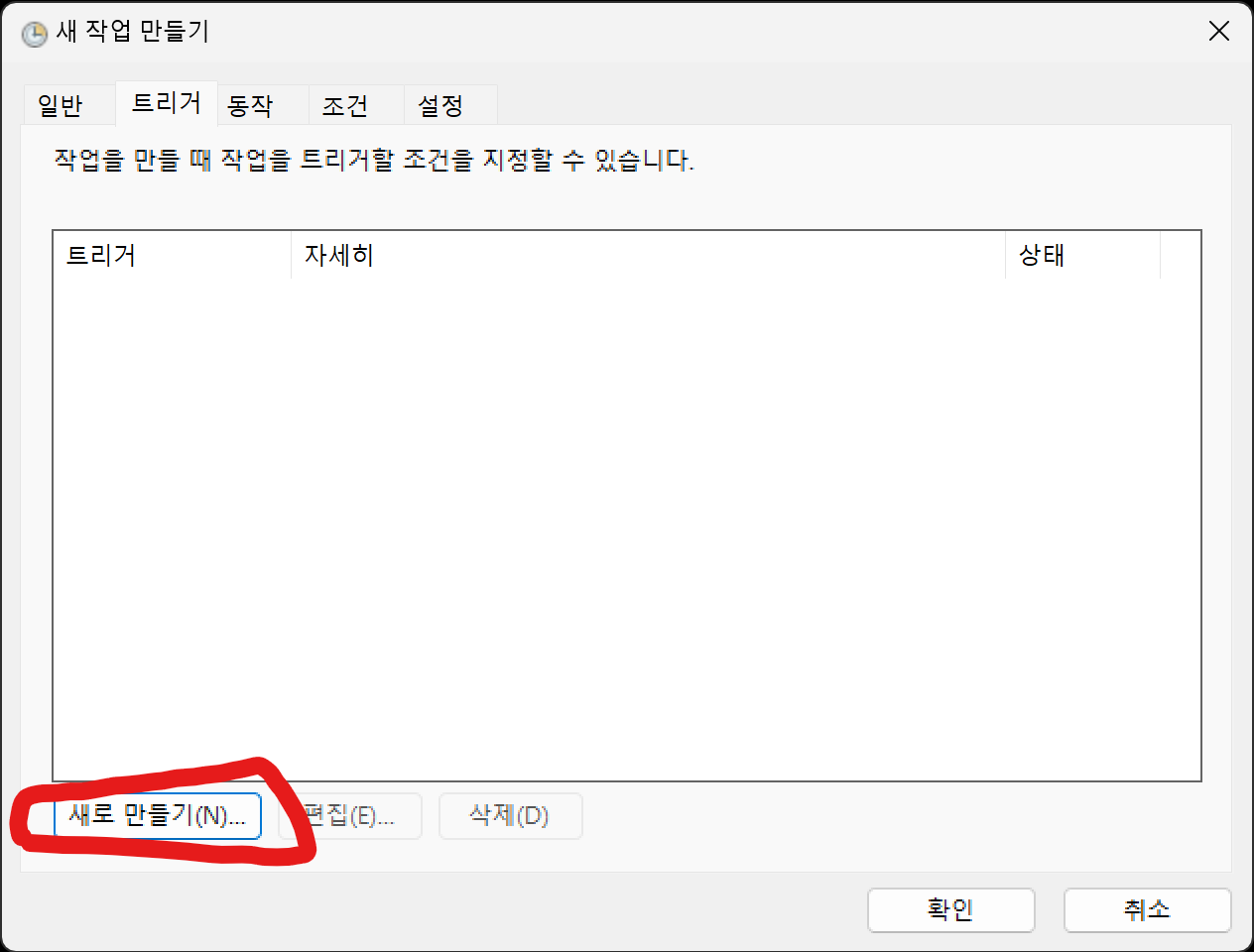
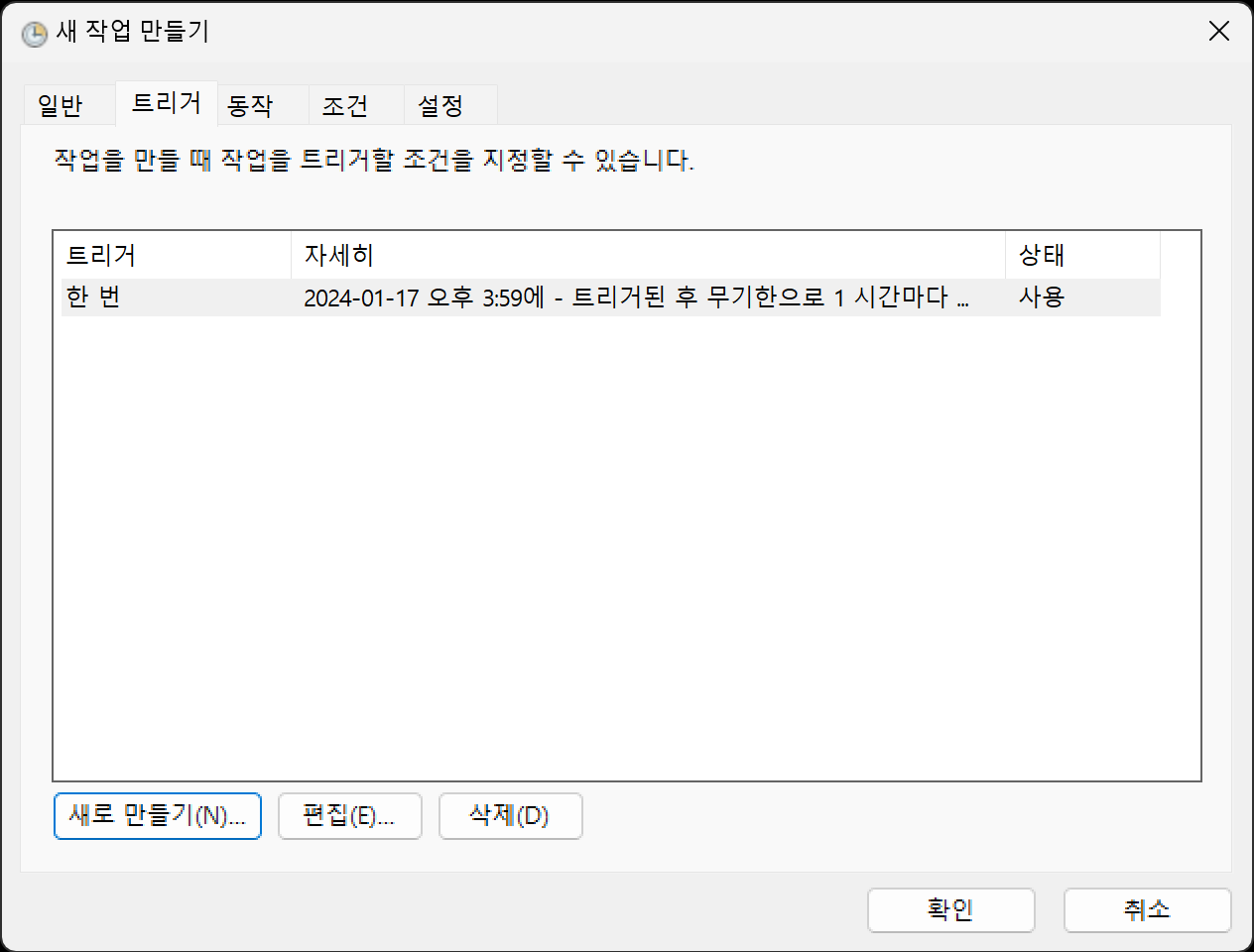
트리거는 매시간으로 만듭니다.
다음과 같이 변경합니다.
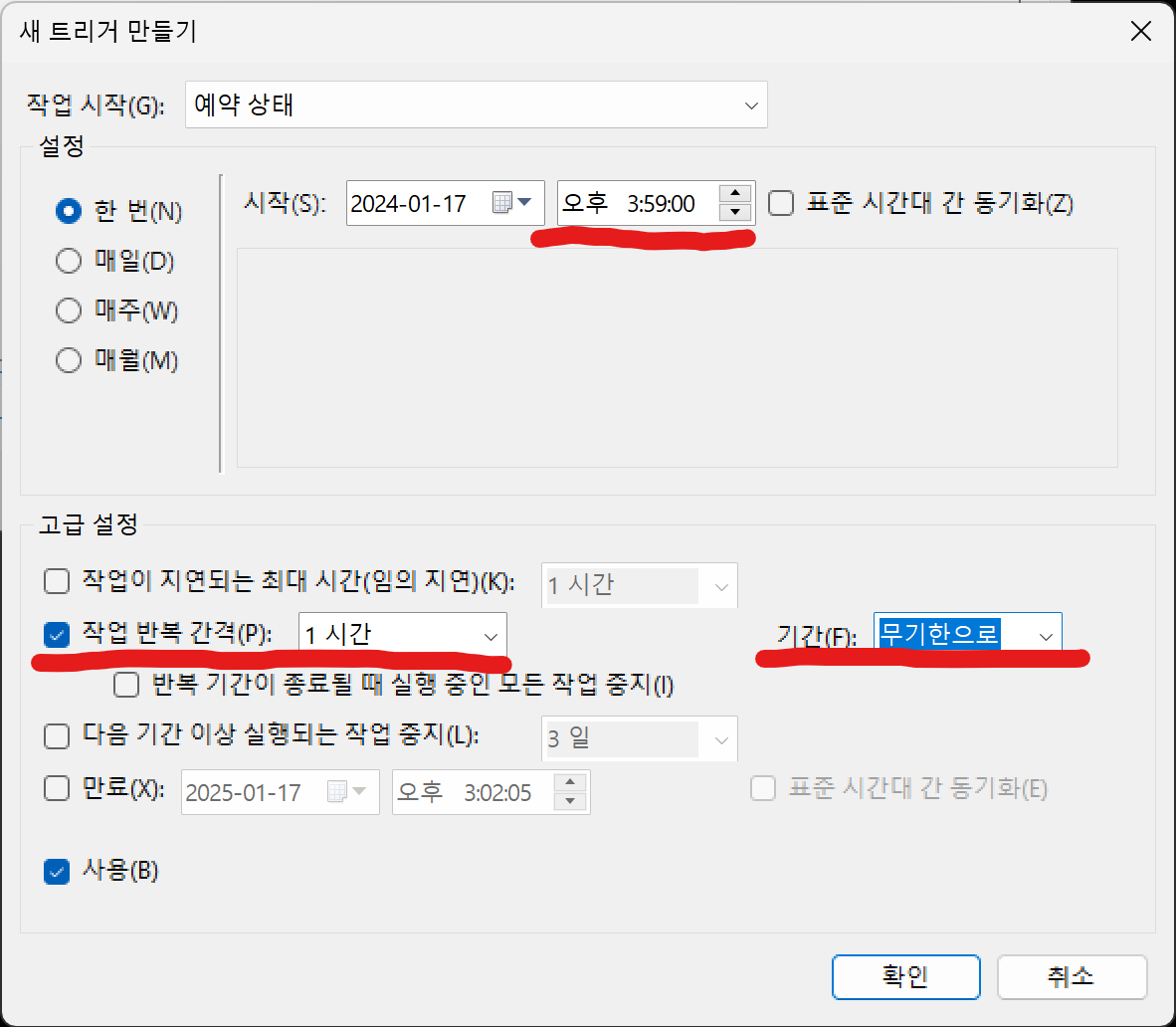
시작 시간, 작업 반복 간격, 기간등을 변경합니다.
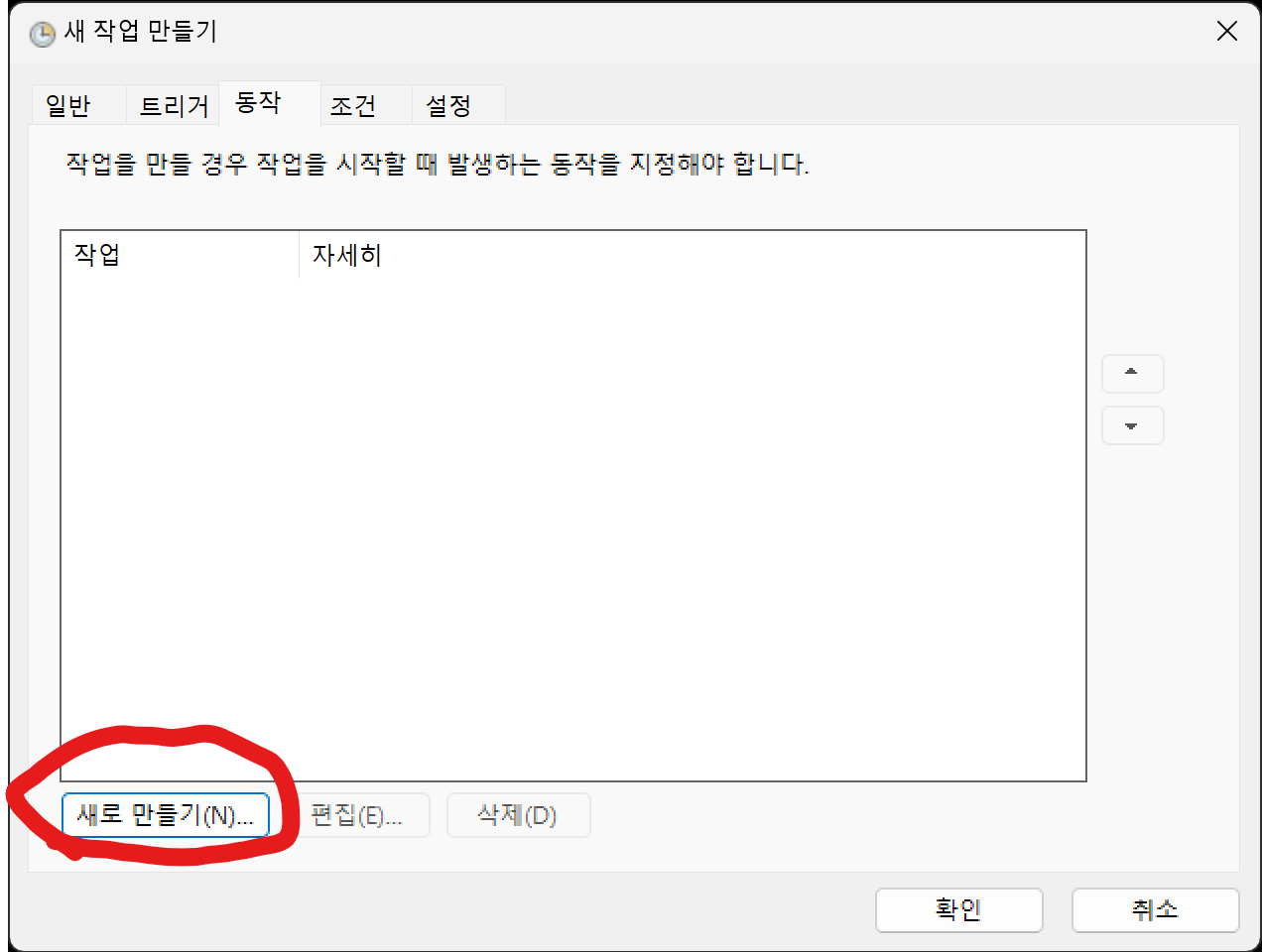
동작을 만듭니다.
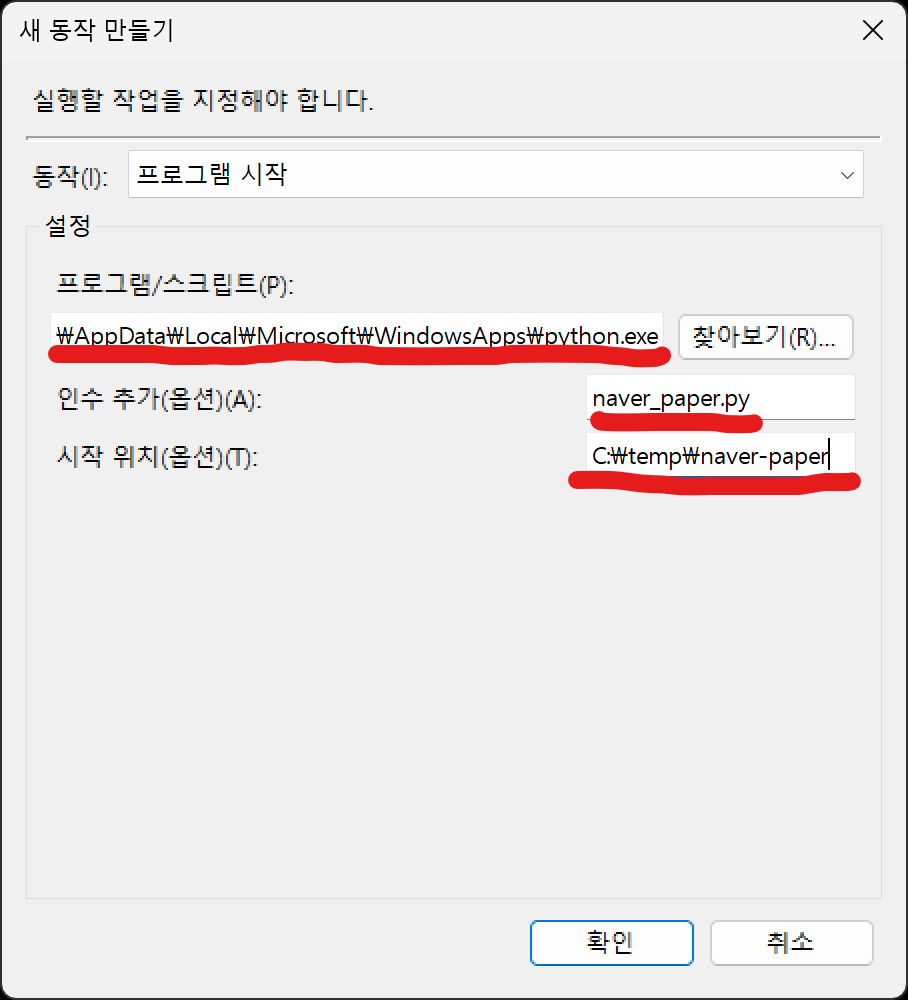
실행하는 python 프로그램은 USER_HOME 폴더를 기준으로 다음과 같습니다. (USER_ID는 각자의 아이디로 바꾸시면 됩니다.)
"C:\Users\USER_ID\AppData\Local\Microsoft\WindowsApps\python.exe"
인수에는 "naver_paper.py"를 입력하고
시작 위치는 "naver_paper.py"가 있는 폴더명을 넣어 줍니다.
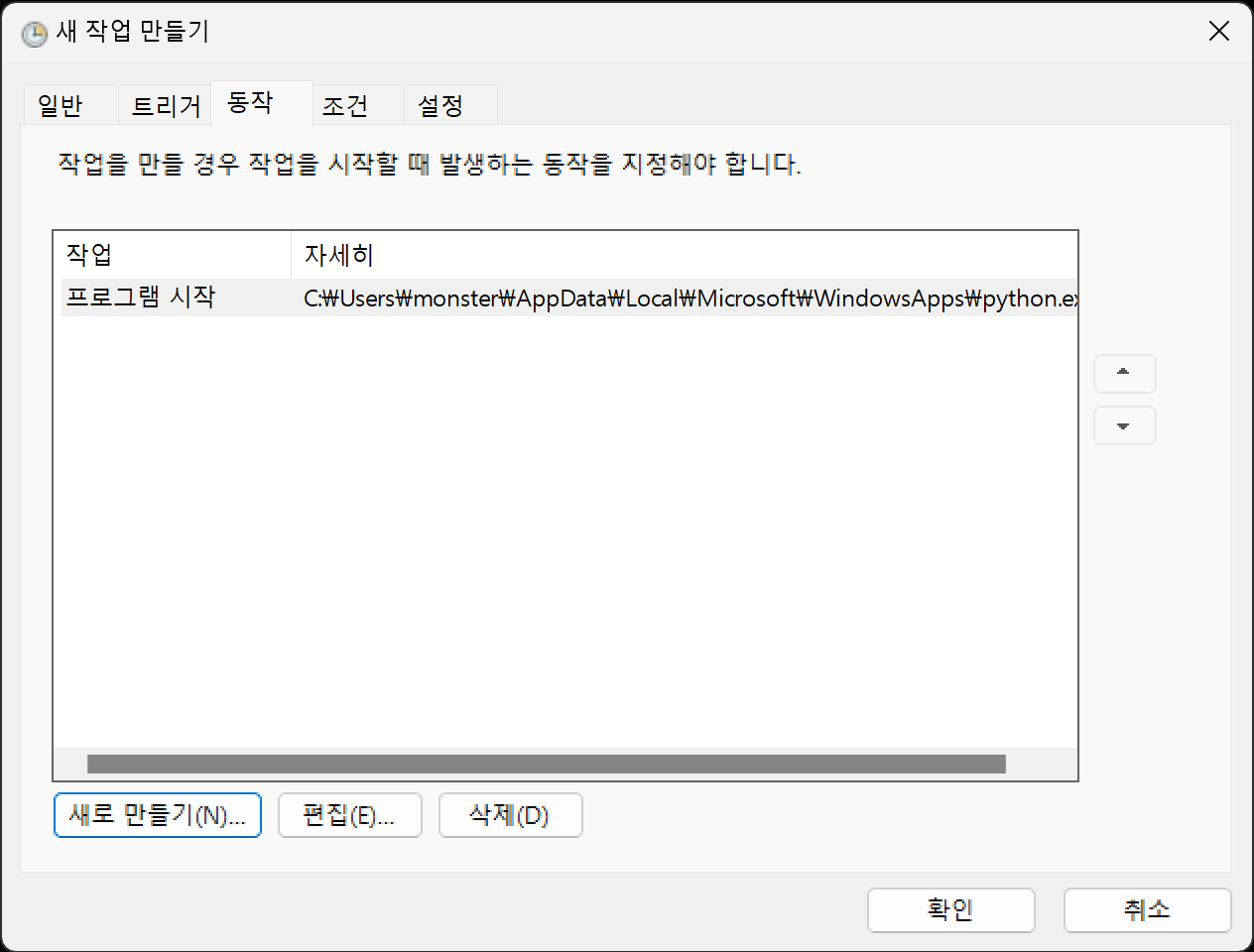
확인을 누르면 작업이 만들어 집니다.
% python requests로 로그인하는 방법은 captcha를 입력하게 되어서 블럭된 상태입니다.
'Windows' 카테고리의 다른 글
| AULA F75 키보드 관련 (충전 표시기 끄기) (2) | 2024.11.26 |
|---|---|
| Visual Studio 2022 Professional "Microsoft.VisualStudio.Validation" 오류 (12) | 2024.10.25 |
| 강원전자 NM-LAD03 사용기 (2) | 2023.09.13 |
| windows11 wsl 관련 (0) | 2023.08.24 |
| Windows11 OpenSSH default shell 설정 (0) | 2023.08.22 |

